
V dnešní době slovo AI zažívá velký boom, všichni o tom někde slyšeli, nebo si vyzkoušeli chatgpt. A co dál? Stát se AI developerem! Wait, co vlastně AI developer dělá? A kde se to dá naučit? V tomto článku rozepisuji svůj pohled na věc, dopředu upozorňuji, že nejsem profík na programování a pouze začínám objevovat tuto cestu. Stay tuned a můžeme se do toho ponořit.
Úvod
V první řadě, proč o tom píšu? Dostal jsem se do bodu, kdy vypravím každému o AI a studuji/zkouším každou novinku, co výjde do světa. Zároveň jsem obklopen vývojáři, ať už na platformě X nebo v práci. Ale hledal jsem další cesty, jak prohloubit svoje znalosti.
Na instagramu (ano, na instagramu) mě zaujal kurz od robotdreams, který přednáší Senior Software Engineer z Microsoftu Lukáš Keller. A byla to trefa do černého. V tomto článku chci shrnout insights z tohoto kurzu a pokusím se přiblížit jednotlivé oblasti v AI.
Pro zajimavost, povedlo se mi ve Whimsicalu vytvořit rekordní mind mapu:) Kurz se skládal z 11 dvouhodinových lekcí, takže možná není čemu se divit.

Pokud si říkáte, proč jsou všechny nodes na jedné straně, příjde mi to přehlednější. Whimsical.
Co je náplní AI developera a jaké jsou jeho skills? Jaké jsou další technické pozice?
Existuje několik rolí, které AI developer může v rámci vývoje rozvíjet jako:
- Software Engineer = stará se o celou architekturu, která pohání LLM model, je to více technická role. Přirovnal bych to k DevOps v rámci AI:) Vyvíjí uživatelské prostředí a vymýšlí, jak se k uživateli dostat co nejrychleji s požadavky na infrastrukturu. Pracuje jednak s closed source modely (jednodušší) nebo s open-source modely (náročnější).
- AI Engineer = stará se o “své” natrénované modely, také o data a trénuje model pomocí customizačních technik, jako je finetuning nebo RAG (Retrieval Augmented Generation), snaží si je přizpůsobit podle svého use case, není ale napřímo vývojář základního base modelu. Ale zásadně ovlivňuje výsledky pro uživatele, pokud použije strukturovaná data, databáze a vytrénuje model tak, jak má. Vhodné pro dataře.
- ML Engineer = vytváří nebo pečuje o základní base model, jak ho vytrénovat pro nejlepší výstupy na datech z různých zdrojů a korigovat výstupy. Technicky a vědecky asi nejsložitější disciplína.
- Další současné nebo nově vznikající pozice:
- Prompt Engineer = jedna z nově žádaných pozicí, stará se o prompty v rámci produktu, aby přinášely uživateli tížené ovoce. Neboli komunikuje co nejlépe s AI. Technicky nejméně náročná pozice ze všech vyjmenovaných, vyžaduje hodně testingu (např. pomocí Langsmith) a evaluaci přesnosti, relevance nebo stručnosti výsledků.
- Product Owner = někdo zkrátka musí vést vývojáře a provádět rozhodnutí, co je a není prioritní pro produkt. Zahrnuji PO také jako roli v rámci AI, i když není vývojářská. Pokud ale rozumí všem oblastem v rámci AI, dostává velkou výhodu pro vývoj AI integrací nebo nového produktu. Samozřejmě potřebuje produktovou znalost.
- Cloud/Server Operator = modely je potřeba rozběhnout na cloudu nebo serveru (zejména open-source), je důležitou součástí celého AI vývoje. Nedokážu určit, jak náročná tato pozice je, ale vím jistě, že je velmi technická:)
Disclaimer: některé pozice vznikají nově, pojmenování neberte dogmaticky a pozice se dost překrývají. Spíše slouží pro přehled.
AI developer si prochází těmito oblastmi…
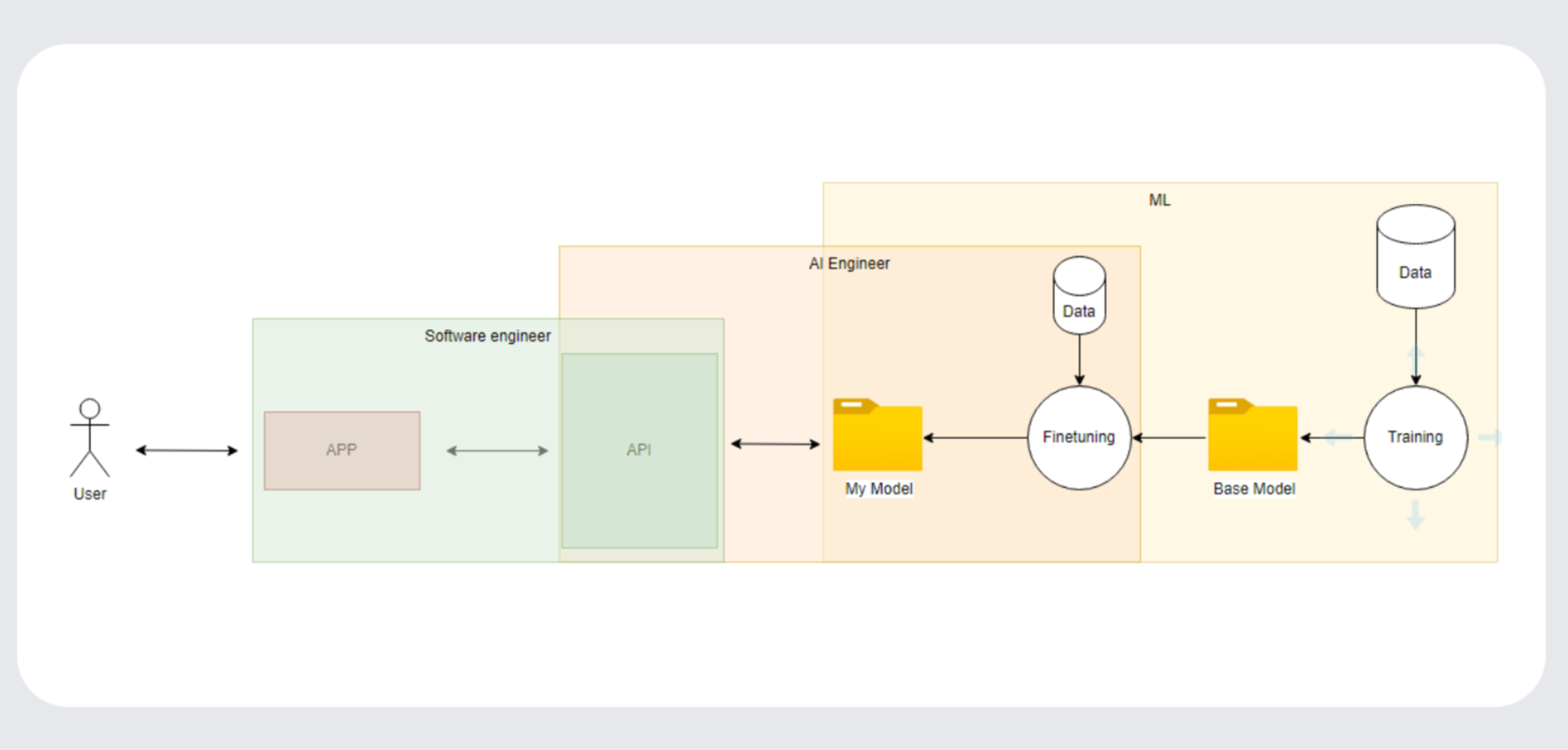
A teď hezky popořadě, jak vypadá flow komunikace s AI modelem a jaké jsou vývojářské “překážky”, které je potřeba zvládnout:
1) Aplikace
- Jedná se o aplikaci, přes kterou user interaguje s modelem. Pěkný chatovací user interface.
- Např. ChatGPT, Claude, Poe.com na webu. Pokud si chcete otestovat prototyp, doporučuji Streamlit.
2) API (Application Programming Interface)
- Pohání aplikaci a interaguje s modelem, přidává také funkcionality navíc v podobě toolů (např. web search, RAG nebo embedings).
- Třetí strany pomocí klasického API klíče, pokud chcete pracovat s modelem lokálně, tak “stačí” stáhnout model, Ollamu a použít výpočetní výkon vašeho zařízení. Otázkou je, jestli vám výkon bude stačit, protože ne každý má k dispozici datové centrum, jako firma OpenAI a další.
3) AI model
- Natrénovaný LLM, kde se chroustá všechna magie pro uživatele.
- Existuje buď: base LLM = upečený například z továrny OpenAI/Anthropic/Meta. Zapotřebí mnoho grafických karet.
- Nebo custom LLM = upečený z vaší továrny, neboli ohnutý podle vašeho způsobu použití, aby vám generoval co nejlepší výsledky. A uživatel byl spokojený.
4) Fine-tuning
- Možnost dotrénovat model podle svého gusta na nových datech. Jedna část dat slouží jako trénovací a druhá část jako testovací. Model se pokouší zlepšovat se na těchto datech své výsledky a validuje si je s testovacími daty, jestli se mýlil nebo ne. Může se stát, že se to “přežene” a na jiných datech nebude fungovat tak dobře.
- Jedná se o trochu náročnější a nákladnější proces, kdy se přetrénuje model na nových datech. Hold to něco stojí a chvilku to trvá. Ale OpenAI má dneska super možnosti, jak dostat k vysněnému finetuningu bez zbytečných technikálií na platformě https://platform.openai.com/. Postará se o trénovací epochy, automaticky rozdělí data na dvě části a vy pak jen čekáte, až se model natrénuje. Následně ho můžete přes API vyvolat a vesele používat.
- Velkou výhodou jsou lepší výsledky pro uživatele!
- Problém ale je, že pokud vyjde nový model (což se děje v poslední době poměrně často), je potřeba opět natrénovat nový model odznova, pokud chcete začít používat ten nejlepší model dostupný na trhu.
5) RAG (Retrieval Augmented Generation)
- Název je příšernej, ale vypovídá o tom, o co se jedná:) Retrieval = vyhledávání v databázi, Augmented = forma rozšíření modelu, Generation = generování kontextu.
- A teď hezky česky: Jedná se o formu customizace modelu, jak opět uživatelovi vylepšit generované výsledky a jak zajistit, aby třeba nehalucinoval. A to jak jinak než na datech. Dost se to na první pohled podobá finetuningu, ale princip je odlišný. RAG probíhá mimo AI model.
- Data jsou uložená mimo model ve vektorové databázi → spustí se vyhledávání → přidají se vyhledaná data k outputu z modelu → hurá, uživatel dostane přesnou odpověď na svou otázku. Oproti tomu fine-tuning trénuje přímo základní model.
- Velkou výhodou oproti finetuningu je možnost napojit RAG na jakýkoliv model, jelikož se vše odehrává ve vektorové databázi (např. ChromaDB). Také není náročné vývojářsky RAG naprogramovat, aby frčel.
- Nevýhodou je, že tam kde nestačí customizace pomocí RAG metody, je potřeba využít i finetuning.
Insight: Pokud se chcete ponořit do metody RAG, doporučuji si pročíst tento dokument, který jsem získal za paywallem. Jednoduše popisuje, o co se jedná a jak RAG funguje. Disclaimer: ano, má 27 stran, ale stojí to za to!
6) Prompt Engineering (pokud vyvíjíme aplikaci nebo produkt)
- Probíhá v kódu na pozadí user interface uživatele. Jsou to klasické prompty, jak je známe z ChatGPT, akorát jsou více promyšlené, strukturované a skládají se třeba z několika částí a instrukcí.
- Pro každý model je potřeba psát jiným “jazykem”, neboli daným prompt formátem podle dokumentace. Např. OpenAI skoro žádný formátování pomocí speciálních atributů nepotřebuje, ale open-source modely jako je Llama nebo Mistral/Mixtral vyžadují svůj “jazyk”, jak komunikovat s modelem. Zde je příklad.
Doporučuji český web https://www.umeligence.cz/chatgpt-priklady, kde je krásný návod pro začátečníky, jak promptovat.
Nebo pro pokročilé, jeden z nejznámější prompt frameworků pro psaní promptů, vždy psát: task, context, examples, persona, format, tone.

Věděli jste, že… Mistral je označení pro model, který nemixuje více expertních modelů v jeden model, ale Mixtral je právě kombinuje. Často se mi stává se zorientovat, který model je který, protože změna je v jednom písmenku:).
Poslední slova
Tento článek je jeden z nejdelších, který jsem kdy psal na tomto blogu. Doufám, že se podařilo ukázat ucelený pohled na AI vývojařinu, kouknout se do střev umělé inteligenci a pochopit, s čím se vývojáři perou. Myslím, že tento insight nebude poslední. Příště zas!


